There are multiple postal code products that can accomplish this task. For an overview, see our general PCCF page https://mdl.library.utoronto.ca/collections/numeric-data/census-canada/postal-code-conversion-file. In this tutorial, we will use the PCCF+ file, which uses a population-weighted random allocation to assign a postal code to a geographic area. This is an alternative method to using the standard PCCF file which uses a Single Link Indicator (SLI) to assign a postal code to the geographic area with the majority of dwellings. The PCCF+ tends to work better when your postal codes are rural or when the “vintage” of your postal codes pans more than one census. See this guide Statistics Canada created for more information on selecting a PCCF product that meets your needs.
The following guide contains two parts and an appendix. In part A, you will start with the postal codes from your dataset and use the PCCF+ to assign Statistics Canada standard geographic identifiers to your postal codes. In part B, you will enrich your final dataset from part A with your dataset and census data. Because the PCCF+ file is a SAS file, part A must be completed using SAS. This guide shows you how to complete part B using SAS as well, and the appendix contains additional code to run part B using R, Stata, SPSS or Python code.
TABLE OF CONTENTS
Part A: Use the PCCF+ to assign standard geographic codes/names to your postal codes
Part B: Adding your dataset and census data
APPENDIX
R Code
Stata Code
SPSS Code
Python Code
Part A: Use the PCCF+ to assign standard geographic codes/names to your postal codes
In this section, you will prepare your postal codes and assign geographic data to them using the PCCF+.
1. First, you need to download the PCCF+ dataset from the MDL website: https://mdl.library.utoronto.ca/collections/numeric-data/census-canada/postal-code-conversion-file.
Choose the census year of interest:
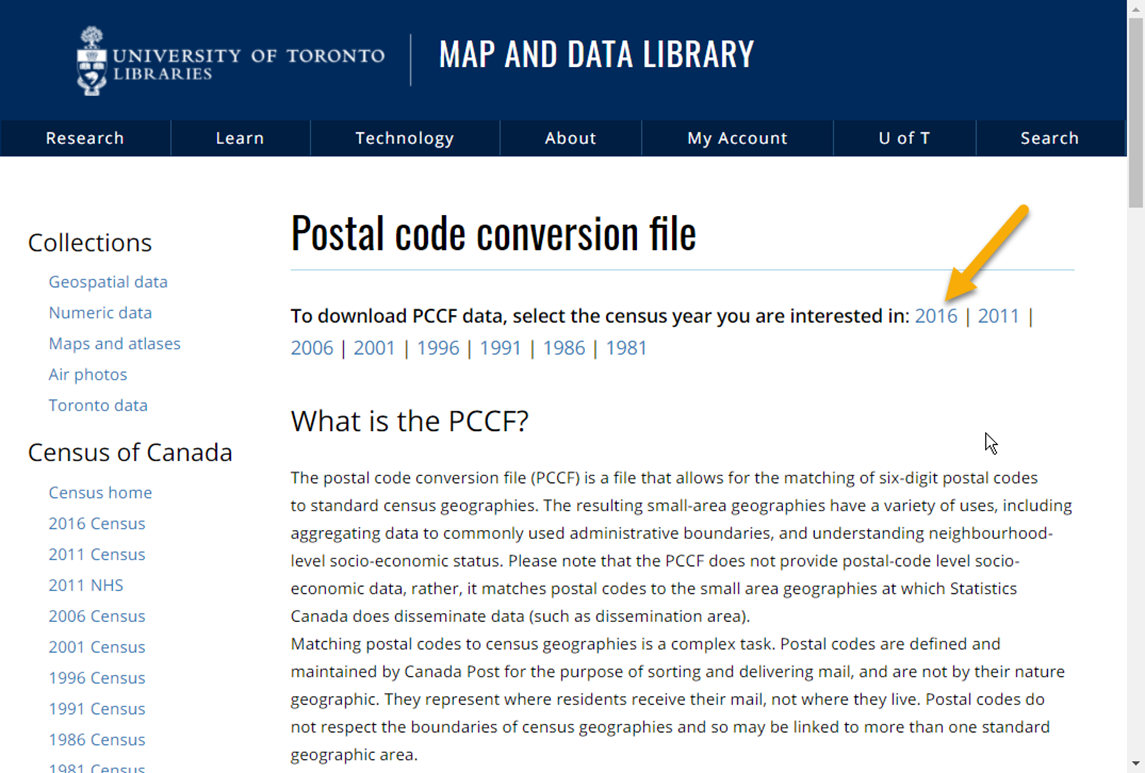
Scroll through the list and find the latest update of PCCF+ file. Click on Access data to download the dataset.

Please carefully read through the end-user license agreement.

At the bottom of the page, click the link to authenticate with your UTORid. The download will then start automatically.
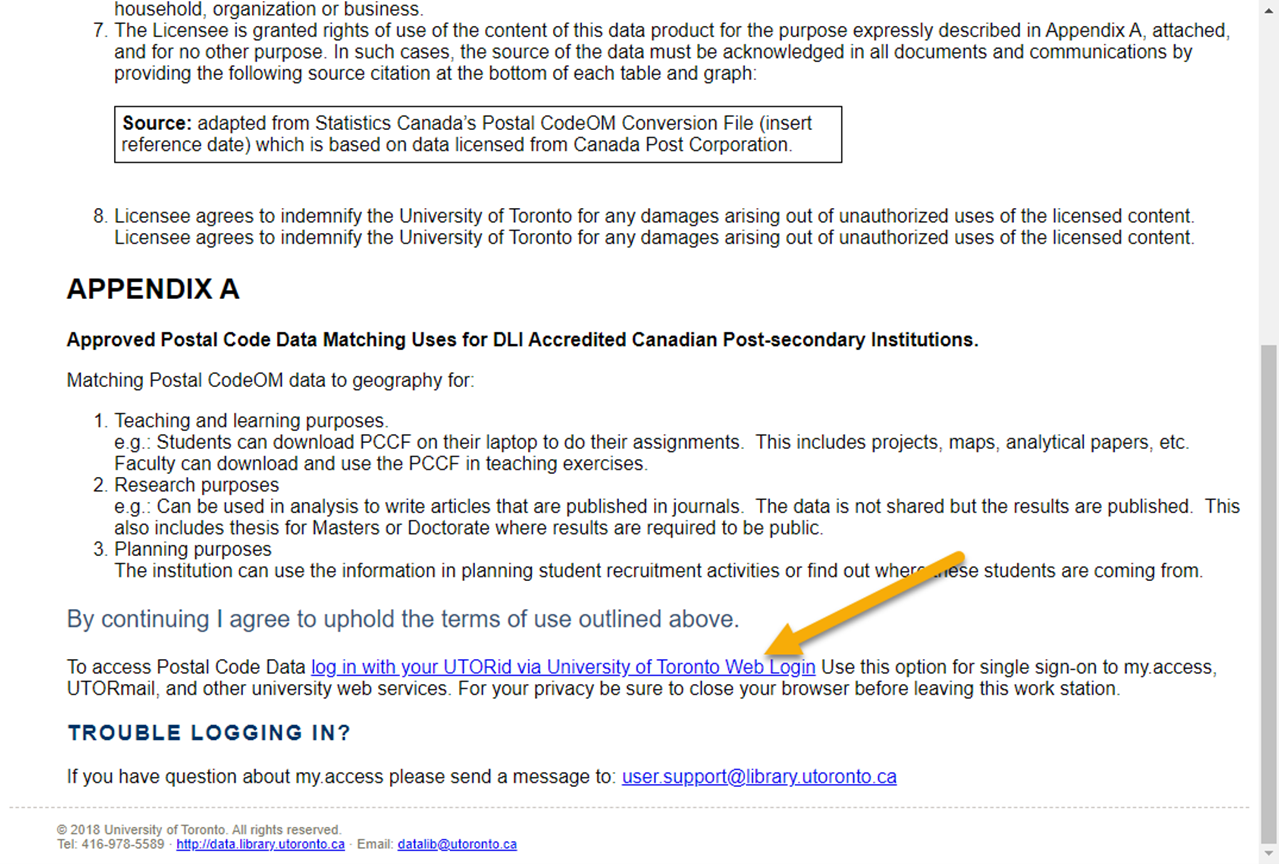
If you wish, move the file from your Downloads folder to some location where you will find it again later.
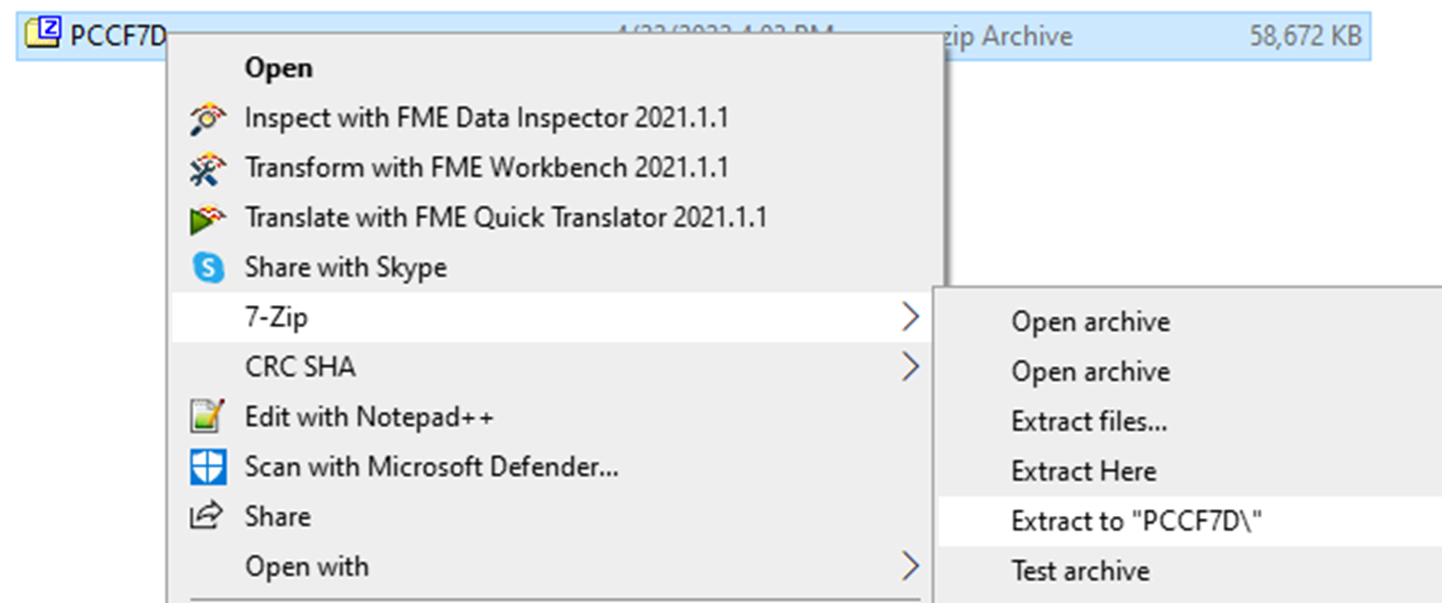
The download is a compressed file which must be uncompressed (or “unzipped”). Right-click on the file and choose Extract All. On a Mac you can simply double-click on the file.
2. To assign geographic data to your postal codes using the PCCF+, you can use the following comprehensive Statistics Canada PCCF+ guide. It explains in detail how to set up and run the PCCF+ with your own postal codes so we will not repeat the work here. The steps in the guide include:
- Creating an input file from your postal codes’ dataset. Be mindful of column names in this step.
- Running PCCF+. This step includes using the PCCF+ dataset and code downloaded from the Map & Data library general PCCF webpage and modifying six lines of SAS code.
- Checking outputs. In this final step, you want to check the output data file to see if it has been populated and the problem files to flag any problematic postal codes.
We complete the steps in this guide using the postal codes from My_dataset.csv. Our input file is My_postalcodes.csv. And in the last step, we save our output dataset as mypostalcodespccfp.csv
Part B. Adding your dataset and census data
In this section of the guide, we will add your dataset and census data to our final dataset from part A.
1. Our final dataset from part A is mypostalcodespccfp.csv. Our dataset is My_dataset.csv. Now we need to download our census dataset.
We can download the census dataset from the CHASS Data Centre website. To access the data from CHASS, you will need to login using your UTORid using the following link: https://login.library.utoronto.ca/index.php?url=http://dc.chass.utoronto.ca/

2. After you login, you will be directed to the CHASS Data Centre homepage. From the menu on the left-hand side, select Canadian Census.

3. This will take you to the Census Analyser page. We will need to select the census profiles by census year and census geography. We will select our census profiles by census year first for this guide. Select 2016 under by Census Year.

4. Then we select the census geography. Select Profile of Dissemination Areas.

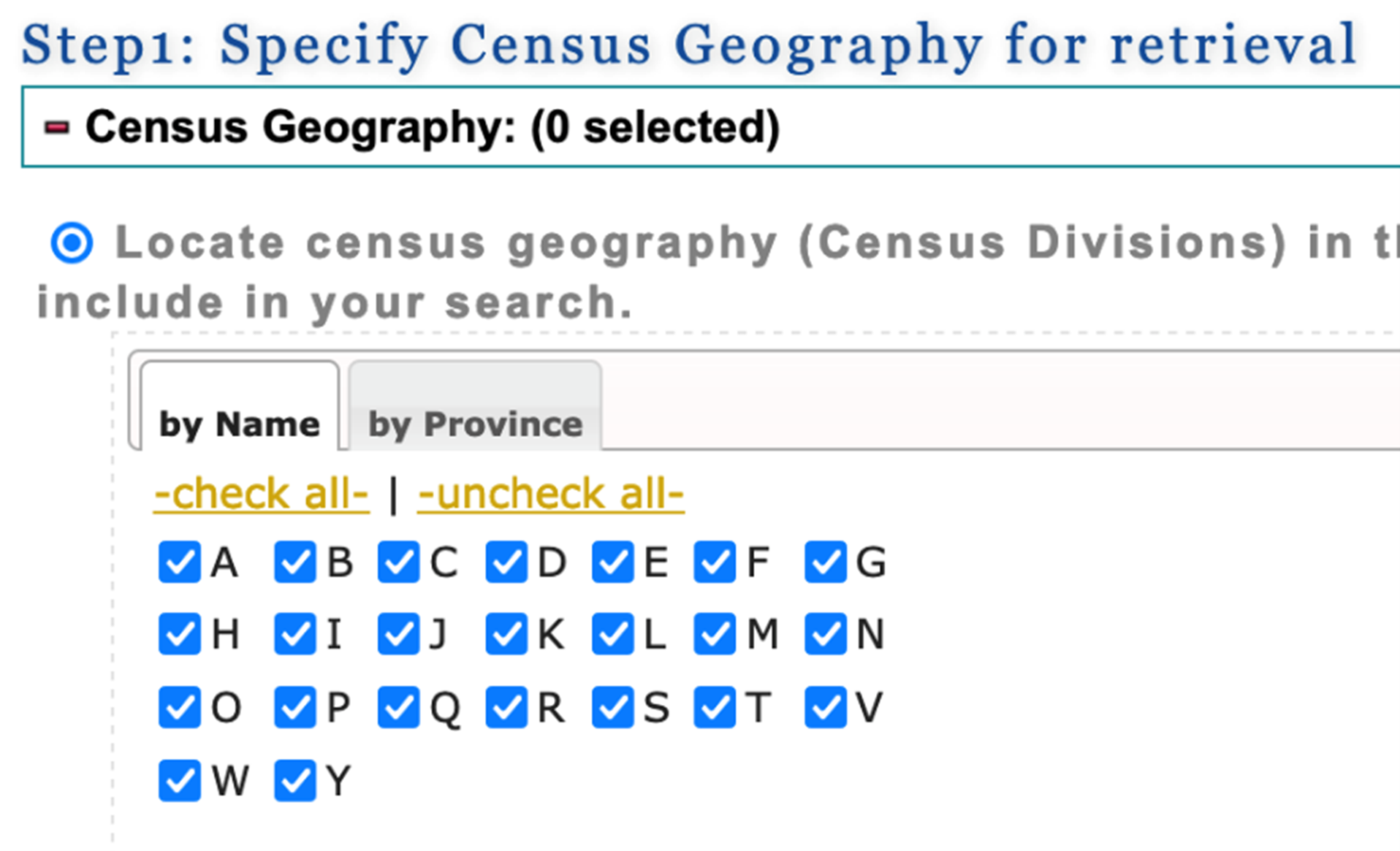
5. This will direct you to a page where you can make additional choices to make your census profile table. In step 1, you can select a subset of regions or select all. For this guide, we will select “check all”.
6. In step 2, you can select the census variables that you are interested in. (Note: you may need to scroll way down the page before you see step 2). The variables are grouped by topic under the topic tabs (eg. Population and dwellings, Age & sex etc). You will find the list of variables under the tabs. To select a variable, click on the check box to the left of the variable description.
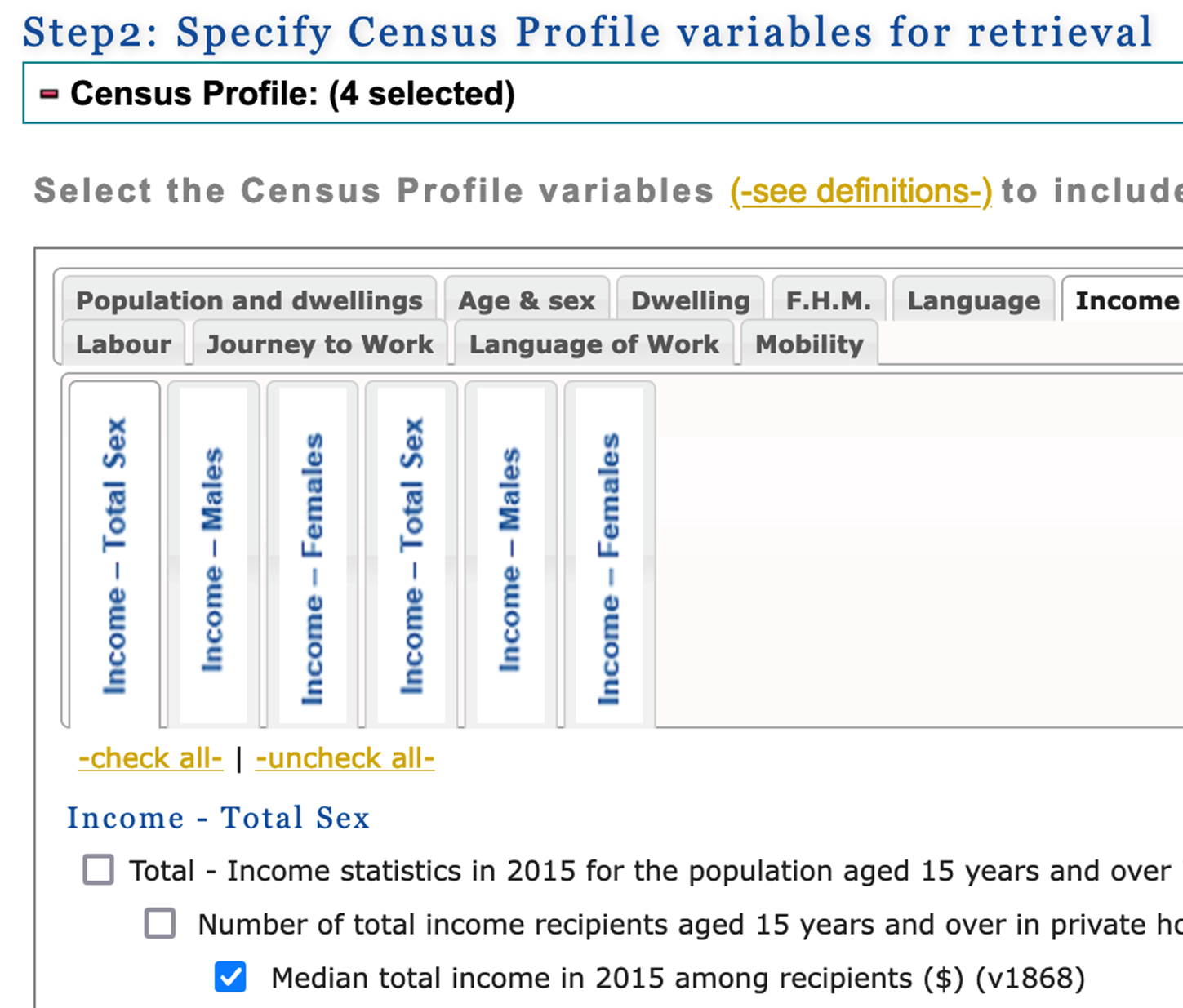
For this guide, we select the following four variables:
- Income - Total Sex / Total - Income statistics in 2015 for the population aged 15 years and over in private households - 100% data / Number of total income recipients aged 15 years and over in private households - 100% data / Median total income in 2015 among recipients ($) (v1868)
- Housing - Total Sex / Total - Owner households in non-farm, non-reserve private dwellings - 25% sample data / Median monthly shelter costs for owned dwellings ($) (v3942)
- Education - Total Sex / Total - Highest certificate, diploma or degree for the population aged 15 years and over in private households - 25% sample data (v4920)
- Education - Total Sex / Total - Highest certificate, diploma or degree for the population aged 15 years and over in private households - 25% sample data / Postsecondary certificate, diploma or degree / University certificate, diploma or degree at bachelor level or above (v4929)
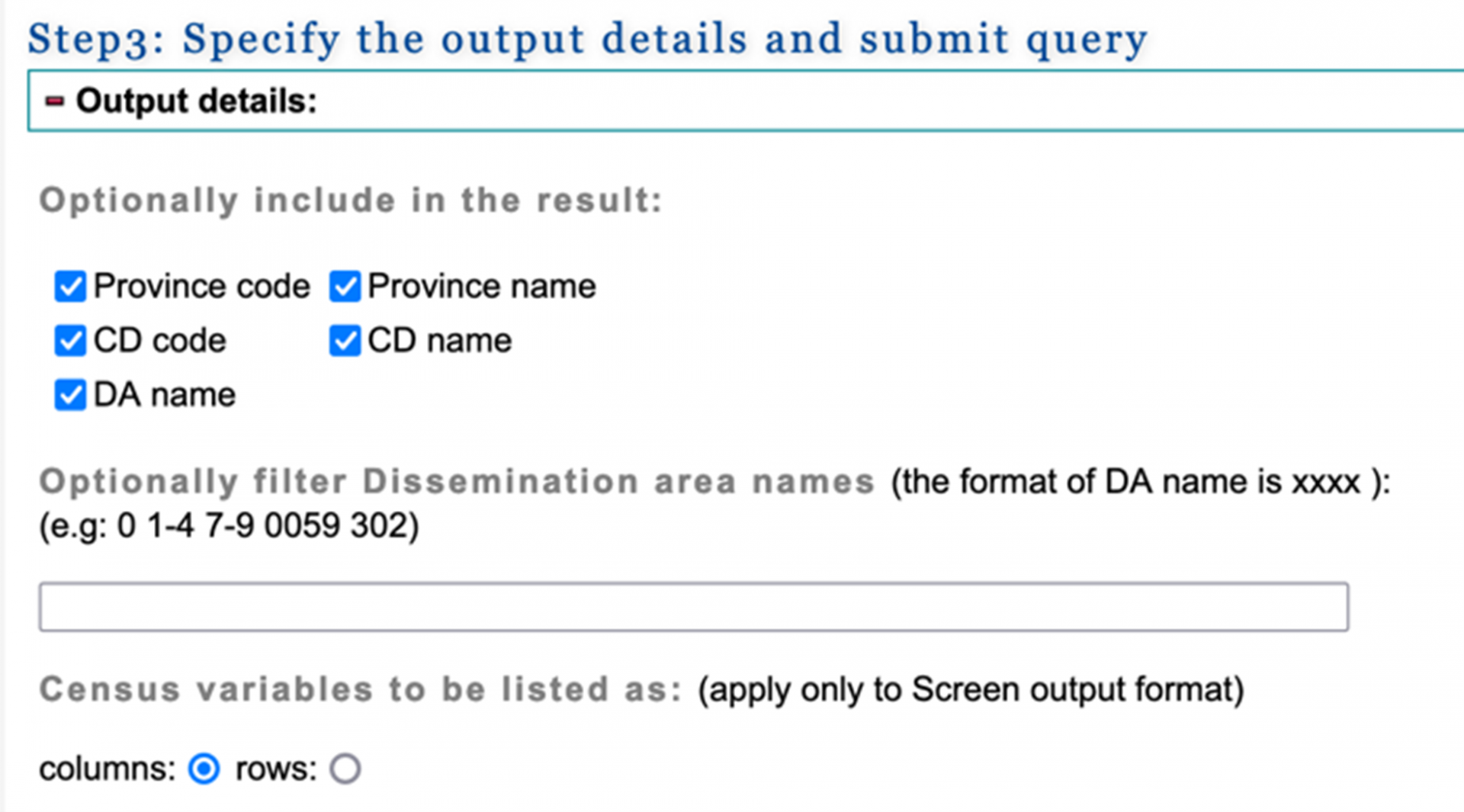
7. In step 3, you can select the geographic variables to be included in the census dataset and the output data format to download the census dataset.
Check all 5 of the geographic variables. In the Select the output format box, under Download to a file, we select Comma-Separated Values (CSV) file for spreadsheet to download the census dataset as a CSV file. Select Submit Query.

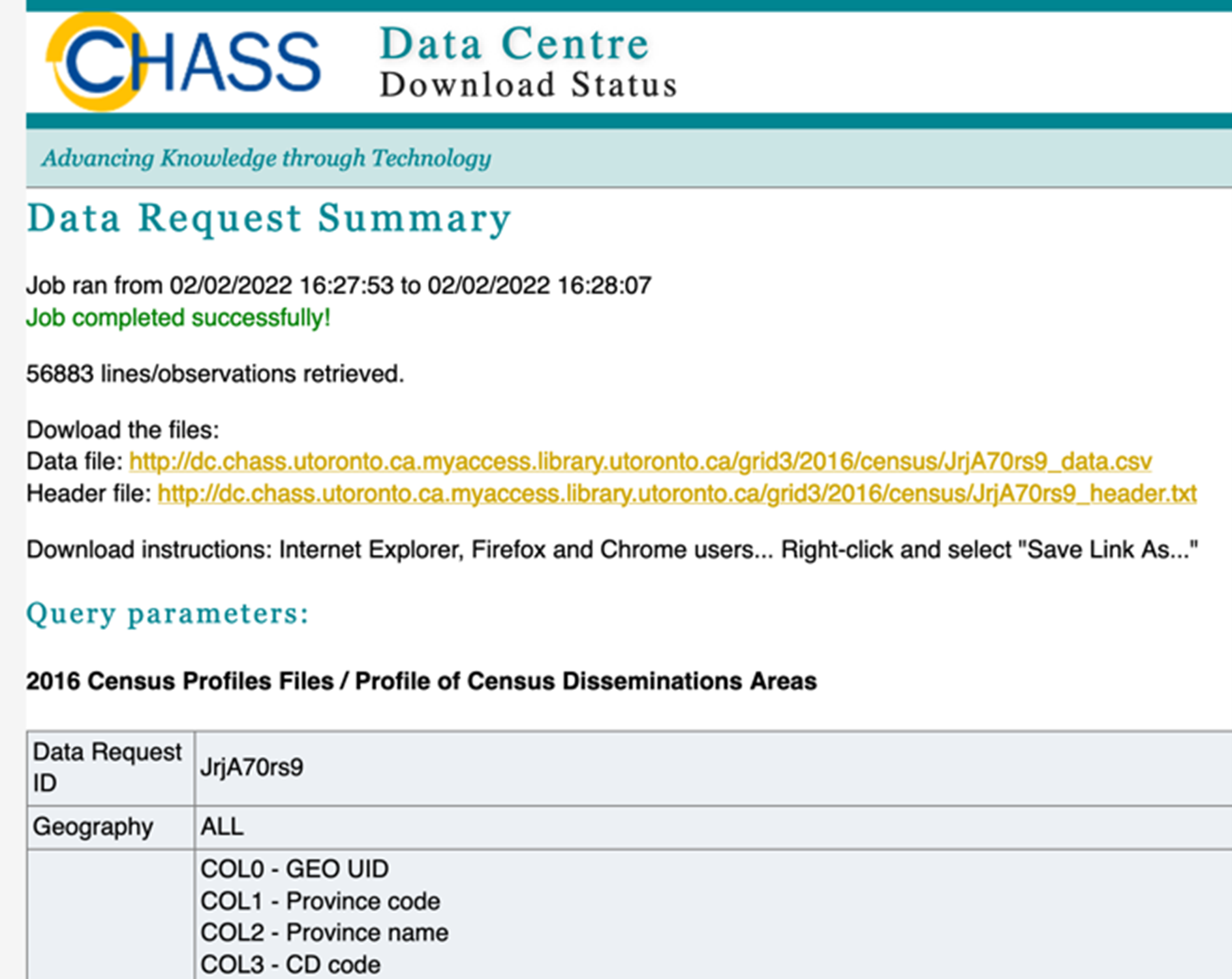
The wizard might take a few minutes to complete the query. When the data request is complete, you will be provided with two links. One to download the data file and another one to download a file with descriptions of the column names in the first data file.
Right-click on the link next to Data file to download the census dataset. Choose Save Link As… We save this data file as census2016.csv.
Now that we have downloaded the census dataset, we have all three data files ready: My_datatset.csv (our dataset), mypostalcodespccfp.csv (our data from part A), and census2016.csv (our census dataset).
We want to enrich the data from part A with our dataset and census data. We will continue to use SAS to combine these three datasets. The code we will run in SAS is described below.
8. In SAS, we open a new editor: go to the File menu>select New Program. We will type the SAS code in the new editor.
9. First, we import our three data files using the following SAS code. The code renames these datasets mydataset, mypostalcodespccfp and census respectively in the context of SAS.
Type and run the code below. Make sure that you modify the file paths to point to those three data files on your computer.
* PCCF+ Guide;
* PART B: Adding your research dataset and census data;
* Instruction:
* - Replace the data file paths below with the respective file paths on your computer;
* STEP 1: Importing datasets
* Import your dataset;
proc import out=work.mydataset
datafile="H:\PCCF Guide\Data\My_dataset.csv"
dbms=csv replace;
getnames=yes;
datarow=2;
run;
* Import data from part A - your postal codes combined with the PCCF+ file;
proc import out=work.mypostalcodespccfp
datafile="H:\PCCF Guide\Data\mypostalcodespccfp.csv"
dbms=csv replace;
getnames=yes;
datarow=2;
run;
*Import the census data file;
proc import out=work.census
datafile="H:\PCCF Guide\Data\census2016.csv"
dbms=csv replace;
getnames=yes;
datarow=2;
run;
10. To run or execute this code, highlight all of these lines of code and click the running man icon on the toolbar .
.
11. Then we combine mydataset and mypostalcodespccfp. We need to prepare these two datasets before we can combine them using the SAS code below.
We rename the postal_code variable in mydataset to pcode to match the variable in mypostalcodespccfp dataset.
The postal codes in the pcode variable in mydataset have a single space between the first three characters or the forward sortation area and the last three characters or the local delivery unit. We remove this space to match the postal codes in mypostalcodespccfp.
* STEP 2: Combine the datasets mydataset and mypostalcodespccfp; * Rename the postal code variable in your dataset pcode; data mydataset; set mydataset; rename postal_code=pcode; run;
* Remove the single space in pcode in mydataset; data mydataset; set mydataset; pcode = compress(pcode); run;
12. We combine mydataset and mypostalcodespccfp by matching the value of the postal codes. To merge two datasets in SAS, you need to sort each dataset by the merging variable first.
Use the SAS code below to sort each dataset by pcode and then merge mydataset and mypostalcodespccfp. We name the merged dataset mydatasetpccfp.
* Sort each dataset by the pcode variable; proc sort data=mydataset; by pcode; run;
proc sort data= mypostalcodespccfp; by pcode; run;
*Merge: combine the two datasets by matching the postalcode variable;
data mydatasetpccfp;
merge mydataset mypostalcodespccfp;
by pcode;
run;
13. We have successfully added our dataset. In the third step, we want to add the census data: we want to combine mydatasetpccfp and census by matching the value of the dauid variable.
We need to prepare these datasets before we can combine them using the SAS code below. We rename the col0 variable dauid in the census to match mydatasetpccfp. Then, we convert this variable from character to numeric to match the data type of the dauid variable in mydatasetpccfp.
* STEP 3: Combine the datasets mydatasetpccfp and census; * Rename the variable col0 dauid in the census dataset to match mydatasetpccfp; data census; set census; rename col0=dauid; run;
*Convert the data type of dauid from character to numeric in the census to match mydatasetpccfp; data census; set census; dauid2 = input(dauid, 10.); drop dauid; rename dauid2=dauid; run;
14. To merge mydatasetpccfp and census, we sort each dataset by dauid first. Then we merge these two datasets by matching the value of dauid. We name the merged dataset mydataset2.
The census dataset is much larger than mydatasetpccfp because it contains dissemination areas from all over Canada outside of the regions in our dataset. Since we are not interested in these additional dissemination areas, we add some additional code in the merge step to keep only the dissemination areas that are part of mydatasetpccfp.
* Sort each dataset by the dauid variable; proc sort data=mydatasetpccfp; by dauid; run;
proc sort data=census; by dauid; run;
* Merge: combine the two datasets by matching the dauid variable and only keep your DAs;
data mydataset2;
merge mydatasetpccfp (in=x) census;
by dauid;
if x=1;
run;
15. In the last step, we export our final dataset. We define a library by specifying a path to our output folder. Then we export mydataset2 as a SAS data file and a CSV data file.
* STEP 4: Export mydataset2; * Create a libname to point to your output folder; libname folder "H:\PCCF Guide\Data";
* Save mydataset2 as a SAS dataset in your output folder; data folder.mydataset2; set work.mydataset2; run;
* Export mydataset2 to CSV in your output folder;
proc export data=work.mydataset2
outfile="H:\PCCF Guide\Data\My_dataset2.csv"
dbms=csv replace;
run;
The complete SAS code file to add our dataset and census data can be downloaded here.
Appendix
The R, Stata, SPSS and Python codes to accomplish the steps in part B (enriching your postal codes/pccf+ with your dataset and census data) can be found below. The datasets used in the code are My_dataset.csv, mypostalcodespccfp.csv and census2016.csv. You need to follow the instructions in part B to download the census dataset.
Key points to keep in mind about these statistical programs:
- R, Stata, SPSS and Python are case sensitive.
- In SPSS, each line of CODE ends with a period.
R Code
# PCCF+ GUIDE
# PART B: Adding your dataset and census data
# Instruction:
# - Replace the data file paths below with the respective file paths on your computer.
# STEP 1: Importing Datasets
# Note: Change all backslashes to forward slashes
# Import your dataset
mydataset <- read.csv("H:/PCCF Guide/Data/My_dataset.csv")
# Import data from part A - your postal codes combined with the PCCF+ file
mypostalcodespccfp <- read.csv("H:/PCCF Guide/Data/mypostalcodespccfp.csv")
# Import the census data file
census <- read.csv("H:/PCCF Guide/Data/census2016.csv")
# STEP 2: Combine the datasets mydataset and mypostalcodespccfp
# Rename the postal code variables in mydataset and mypostalcodespccfp pcode
names(mydataset)[names(mydataset)=="Postal.Code"] <- "pcode"
names(mypostalcodespccfp)[names(mypostalcodespccfp)=="PCODE"] <- "pcode"
# Remove the single space in pcode in mydataset
mydataset$pcode <- gsub(" ", "", mydataset$pcode)
# Merge: combine the two datasets by matching the pcode variable
mydatasetpccfp <- merge(mydataset, mypostalcodespccfp, by="pcode")
# STEP 3: Combine the datasets mydatasetpccfp and census
# Rename the DA variables to dauid in mydatasetpccfp and census
names(mydatasetpccfp)[names(mydatasetpccfp)=="DAuid"] <- "dauid"
names(census)[names(census)=="COL0"] <- "dauid"
# Merge: combine the two datasets by matching the dauid variable
mydataset2 <- merge(mydatasetpccfp, census, by="dauid", all.x=TRUE)
# STEP 4: Export mydataset2
# Export mydataset2 to CSV in your output folder
write.csv(mydataset2,"H:/PCCF Guide/Data/My_dataset2.csv", row.names=FALSE)
Stata Code
* PCCF+ Guide
* PART B: Adding your dataset and census data
>* Instruction:
* - Replace the data file paths below with the respective file paths on your computer.
* STEP 1: Adding your dataset
* Import your dataset
insheet using "H:\PCCF Guide\Data\My_dataset.csv", clear
* Rename the postal code variable in your dataset pcode
rename postalcode pcode
* Remove the space in pcode
replace pcode = subinstr(pcode, " ", "", .)
* Sort by pcode
sort pcode
* Save
save "H:\PCCF Guide\Data\mydataset.dta", replace
* Import the mypostalcodespccfp data file
* Note: The following import line of code is typed over a few lines
insheet coder version id pcode pr dauid db db_ir2016 csduid csdname csdtyp ///
cma cmatype cmaname ctname tracted saccode sactype ccsuid feduid fedname ///
dpluid dpltype dplname eruid ername caruid carname popctrrapuid ///
popctrraname popctrratype popctrraclass csize csizemiz hruid hrename ///
hrfname ahruid ahrename ahrfname sli rep_pt_type rpf pctype dmt h_dmt ///
dmtdiff po qi source lat lon link_source link ncd ncsd prec comm_name ///
airlift instflag resflag inuitlands btippe atippe qabtippe qnbtippe ///
dabtippe dnbtippe qaatippe qnatippe daatippe dnatippe impflg da11uid ///
db11uid da06uid da01uid ea96uid ea91uid ea86uid ea81uid ///
using "H:\PCCF Guide\Data\mypostalcodespccfp.csv", clear
* Sort by pcode
sort pcode
* Save
save "H:\PCCF Guide\Data\mypostalcodespccfp.dta", replace
* Merge: Combine the Stata datasets mydataset and mypostalcodespccfp
use "H:\PCCF Guide\Data\mydataset.dta", clear
merge 1:1 pcode using "H:\PCCF Guide\Data\mypostalcodespccfp.dta"
drop _merge
save "H:\PCCF Guide\Data\mydatasetpccfp.dta", replace
* STEP 2: Adding census data
>* Import the mydatasetpccfp data file
use "H:\PCCF Guide\Data\mydatasetpccfp.dta", clear
* Sort by dauid
sort dauid
* Save
save "H:\PCCF Guide\Data\mydatasetpccfp.dta", replace
* Import the census data file
insheet using "H:\PCCF Guide\Data\census2016.csv", clear
* Rename the variable col0 dauid
rename col0 dauid
* Sort by dauid
sort dauid
* Save
save "H:\PCCF Guide\Data\census2016.dta", replace
* Merge: Combine the datasets mydatasetpccfp and census and only keep your DAs
use "H:\PCCF Guide\Data\mydatasetpccfp.dta", clear
merge 1:1 dauid using "H:\PCCF Guide\Data\census2016.dta"
keep if _merge==1|_merge==3
drop _merge
save "H:\PCCF Guide\Data\mydataset2.dta", replace
* STEP 3: Export mydatset2
* Export mydataset2 to CSV in your output folder
outsheet using "H:\PCCF Guide\Data\My_dataset2.csv", comma replace
SPSS Code
* Encoding: UTF-8.
* PCCF+ GUIDE.
* PART B: ADDING YOUR DATASET AND CENSUS DATA.
* Instructions:
- Replace the data file paths below with the respective file paths on your computer
- Run the code below in chunks. The chunks of code are separated by at least one line of space.
>* STEP 1: Adding your dataset.
* IMPORT My_dataset.csv, PREPARE it for merging & SAVE it as My_dataset.sav.
GET DATA /TYPE=TXT /FILE='H:\PCCF Guide\Data\My_dataset.csv'
/ENCODING=LOCALE
/DELCASE = LINE
/DELIMITERS = ","
/ARRANGEMENT = DELIMITED
/FIRSTCASE = 2
/VARIABLES= PostalCode A Age A.
COMPUTE PostalCode = replace(PostalCode, " ", "").
SORT CASES BY PostalCode (A).
SAVE OUTFILE='H:\PCCF Guide\Data\My_dataset.sav'
/RENAME=(PostalCode = PCODE).
EXECUTE.
* IMPORT mypostalcodespccfp.csv, PREPARE it for merging & SAVE it as mypostalcodespccfp.sav.
GET DATA /TYPE=TXT /FILE='H:\PCCF Guide\Data\mypostalcodespccfp.csv'
/ENCODING=LOCALE
/DELCASE = LINE
/DELIMITERS = ","
/ARRANGEMENT = DELIMITED
/FIRSTCASE = 2
/VARIABLES= CODER A VERSION A ID A PCODE A PR A DAuid F8.0 DB A
DB_ir2016 A CSDuid A CSDname A CSDtyp A CMA A CMAtype A CMAname A CTname A Tracted A SACcode A SACtype A
CCSuid A FEDuid A FEDname A DPLuid A DPLtype A DPLname A ERuid A ERname A CARuid A CARname A PopCtrRAPuid A
PopCtrRAname A PopCtrRAtype A PopCtrRAclass A CSize A CSizeMIZ A HRuid A HRename A HRfname A AHRuid A AHRename A
AHRfname A SLI A Rep_Pt_type A RPF A PCtype A DMT A H_DMT A DMTDIFF A PO A QI A Source A Lat A Long A Link_Source A
Link A nCD A nCSD A PREC A Comm_Name A AirLift A InstFlag A Resflag A InuitLands A BTIPPE A ATIPPE A QABTIPPE A
QNBTIPPE A DABTIPPE A DNBTIPPE A QAATIPPE A QNATIPPE A DAATIPPE A DNATIPPE A IMPFLG A DA11uid A DB11uid A DA06uid A DA01uid A EA96uid A EA91uid A EA86uid A EA81uid A.
SORT CASES BY PCODE (A).
SAVE OUTFILE='H:\PCCF Guide\Data\mypostalcodespccfp.sav'.
EXECUTE.
*MERGE My_dataset.sav and mypostalcodespccfp.sav & SAVE it as mydatasetpccfp.sav.
MATCH FILES
/FILE='H:\PCCF Guide\Data\My_dataset.sav'
/FILE='H:\PCCF Guide\Data\mypostalcodespccfp.sav'
/BY PCODE.
SORT CASES BY DAuid (A).
ALTER TYPE DAuid (A8).
>EXECUTE.
SAVE OUTFILE='H:\PCCF Guide\Data\mydatasetpccfp.sav'.
EXECUTE.
* STEP 2: Adding census data.
* IMPORT census2016.csv, PREPARE it for merging & SAVE it as census2016.sav.
>GET DATA /TYPE=TXT /FILE='H:\PCCF Guide\Data\census2016.csv'
/ENCODING=LOCALE
/DELCASE = LINE
/DELIMITERS = ","
/ARRANGEMENT = DELIMITED
/FIRSTCASE = 2
/VARIABLES= COL0 A COL1 A COL2 A COL3 A COL4 A COL5 A COL6 A COL7 A COL8 A COL9 A.
COMPUTE COL0 = replace(COL0, '"', "").
EXECUTE.
SORT CASES BY COL0 (A).
ALTER TYPE COL0 (A8).
EXECUTE.
SAVE OUTFILE='H:\PCCF Guide\Data\census2016.sav' /RENAME=(COL0 = DAuid).
EXECUTE.
>*MERGE mydatasetpccfp.sav and census2016.sav & SAVE it as mydataset2.sav.
MATCH FILES
/FILE='H:\PCCF Guide\Data\mydatasetpccfp.sav' /IN=mypostalcodes
/FILE='H:\PCCF Guide\Data\census2016.sav'
/BY DAuid.
SELECT IF mypostalcodes.
EXECUTE.
DELETE VARIABLES mypostalcodes.
EXECUTE.
SAVE OUTFILE='H:\PCCF Guide\Data\mydataset2.sav'.
EXECUTE.
* STEP 3: Export mydatset2.sav to CSV to your output folder.
SAVE TRANSLATE OUTFILE='H:\PCCF Guide\Data\My_dataset2.csv' /TYPE=CSV /MAP /REPLACE /FIELDNAMES /CELLS=LABELS.
EXECUTE.
Python Code
# PCCF+ GUIDE
# PART B: Adding your dataset and census data
# Instruction:
#- Replace the data file paths below with the respective file paths on your computer.
# STEP 1: Importing Datasets
# Note: Change all backslashes to forward slashes
# Import necessary Python library
import pandas as pd
# Import your dataset
>mydataset = pd.read_csv("H:/PCCF Guide/Data/My_dataset.csv")
# Import data from part A - your postal codes combined with the PCCF+ file
mypostalcodespccfp = pd.read_csv("H:/PCCF Guide/Data/mypostalcodespccfp.csv", encoding="latin-1")
# Import the census data file
census = pd.read_csv("H:/PCCF Guide/Data/census2016.csv", encoding="latin-1")
# STEP 2: Combine the datasets mydataset and mypostalcodespccfp
# Rename the postal code variables in mydataset and mypostalcodespccfp pcode
mydataset = mydataset.rename({'Postal Code':'pcode'}, axis=1)
mypostalcodespccfp = mypostalcodespccfp.rename({'PCODE':'pcode'}, axis=1)
# Remove the single space in pcode in mydataset
# Note: Ignore the warning
import warnings
warnings.filterwarnings("ignore")
for index in range(0,len(mydataset)):
mydataset["pcode"][index] = mydataset["pcode"][index].replace(" ", "")
warnings.resetwarnings()
# Merge: combine the two datasets by matching the pcode variable
mydatasetpccfp = mydataset.merge(mypostalcodespccfp, how="right", on="pcode")
# STEP 3: Combine the datasets mydatasetpccfp and census
# Rename the DA variables to dauid in mydatasetpccfp and census
mydatasetpccfp = mydatasetpccfp.rename({'DAuid':'dauid'}, axis=1)
census = census.rename({'COL0':'dauid'}, axis=1)
# Merge: combine the two datasets by matching the dauid variable
mydataset2 = mydatasetpccfp.merge(census, how="left", on="dauid")
# STEP 4: Export mydatset2
# Export mydataset2 to CSV in your output folder
mydataset2.to_csv("H:/PCCF Guide/Data/My_dataset2.csv", index=False)