TABLE OF CONTENTS
Set up environment
Cleaning data in python
- Download Dataset
- Load dataset into Spyder
- Subset
- Drop data
- Transform data
- Create new variables
- Rename variables
- Merge two datasets
- A few last words
SET UP ENVIRONMENT
Software
If you are using Python for data analysis, we recommend the Anaconda Scientific Python Distribution. It is completely free, and ideal for processing data as well as for performing predictive analysis and scientific computing. You can get the latest version of Anaconda at https://www.anaconda.com/distribution/. It's available for Windows, macOS, and Linux. For more information about getting started with Anaconda and other Anaconda-related support, please refer to https://docs.anaconda.com/anaconda/.
After you download the Anaconda distribution to your local machine, install it and open Anaconda Navigator. A number of applications are available by default. For this tutorial, Spyder will be used.
Spyder is an open source cross-platform Integrated Development Environment (IDE) for data science. It integrates essential libraries for data analysis, including NumPy, SciPy, and pandas — all of which will be used in this tutorial.

Launch Spyder.
You will see a similar interface as below: the left part of the application is a text editor. The right part is the console. You can write your code in both these areas. The text editor allows you to write multiple lines of codes, edit them, save them and execute them all together. The console allows the input and execution of (often single lines of) code without the editing or saving functionality.
For this tutorial, we are writing our code directly in the console.
The results of our code will also appear in the console.

If you are brand new to Spyder, the application comes with a helpful tutorial. This can be launched by clicking Help (at the top menu) > Spyder tutorial.
This Help tool can also be accessed by clicking the Help tab (above the console, on the right). This tool allows you to search for different commands or python objects, and get more information and/or instructions about them. Alternatively, you can highlight commands or objects written in the editor/console and type Ctrl + I.
More functions of the Help section will be introduced later in this tutorial.

Lastly, you can personalize the font, background color, theme and other appearance properties of Sypder. This can be done by clicking Tools (at the top menu) > Preferences. Below is an example of a dark background theme in Spyder.

Data analysis packages in Python
For data analysis in Python, we recommend several libraries (also referred to as packages). A Python library is a collection of functions and methods that allow you to executre complex actions without writing long lines of code. All these libraries are included in the Spyder platform and can simply be imported and used. These include:
- pandas: a library providing high-performance, easy-to-use data structures and data analysis tools. Complete documentation can be found here (https://pandas.pydata.org/pandas-docs/stable/index.html). You can also check out a 10-minute tour of pandas (https://www.youtube.com/watch?v=_T8LGqJtuGc) from Wes McKinney (https://wesmckinney.com/)
- NumPy: the fundamental package for scientific computing
- matplotlib: the most popular Python library for producing graphs and other 2D data visualizations
- SciPy: a collection of packages addressing a number of different standard problem domains in scientific computing
- sklearn: a machine learning library
CLEANING DATA IN PYTHON
This tutorial will cover the basic steps needed for cleaning data using Python.
Download Dataset
The dataset used in this tutorial is the Canadian Community Health Survey, 2012: Mental Health Component. You can directly access the dataset from here: https://search1.odesi.ca/#/details?uri=%2Fodesi%2Fcchs-82M0013-E-2012-m…, or you can go to odesi.ca and search for the term "CCHS 2012". Choose the entry, "Canadian Community Health Survey, 2012: Mental Health Component".
After loading the page, click "Explore & Download".
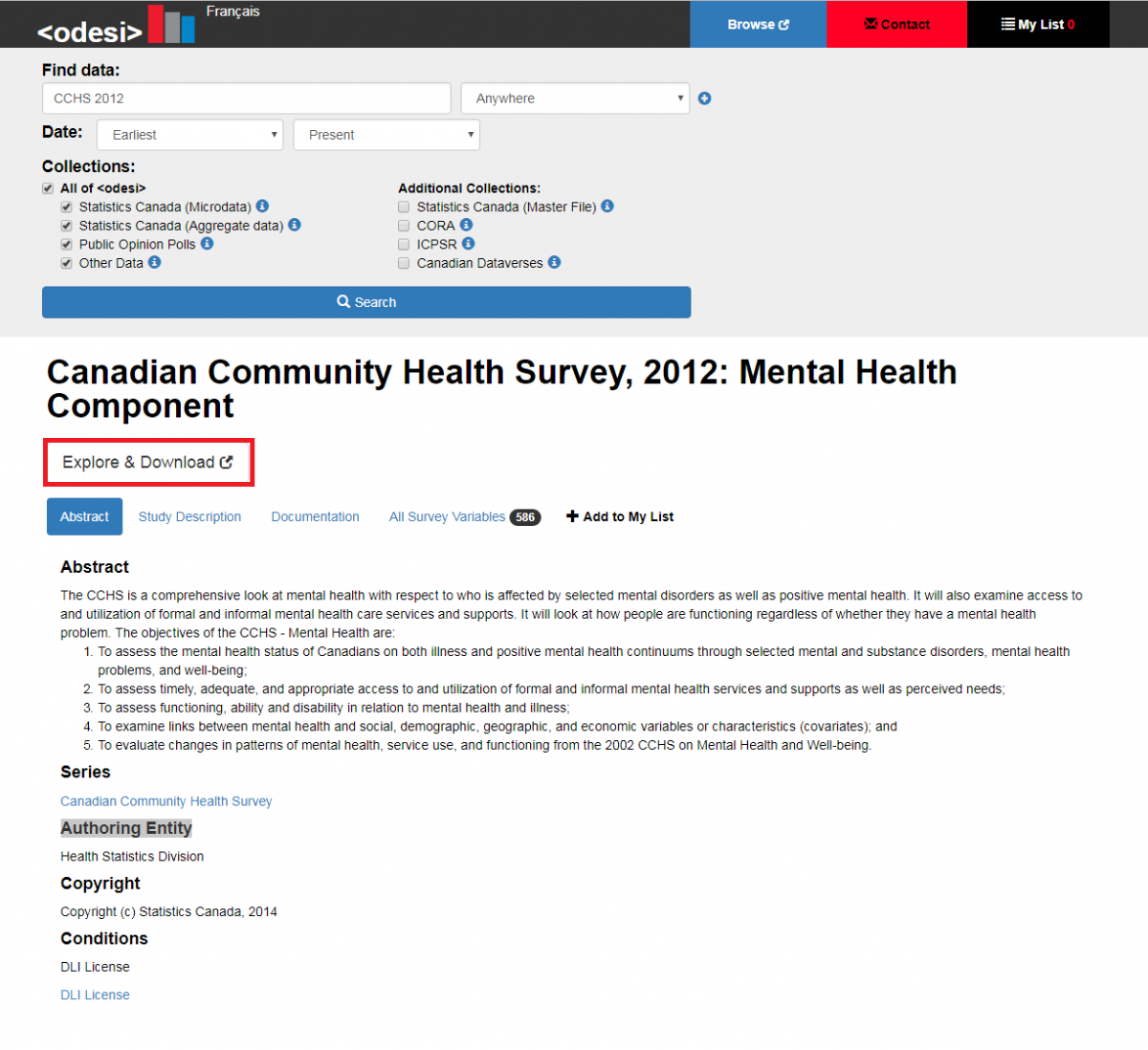
In this new page, find the "Download" button on the top right corner.

In the download page, from the "select the data format" drop-down menu, pick "Comma Separated Value file" for a csv file that python can work with. Check the "Include documentation" box, and then click "DOWNLOAD" to download the dataset and the related documentation in a compressed zip file.

This downloaded file must be unzipped before it can be used. If this is unfamiliar to you, this tutorial covers unzipping files in both windows and mac operating systems.
You will find a csv file and a PDF file in the unzipped folder. The csv file contains the data we will be cleaning, and the PDF file contains the metadata in the form of a codebook for all variables in this dataset. We will refer to the codebook if we would like more information on a certain variable.
Load dataset into Spyder
After you open Spyder, you can direct it to the dataset that you want to clean. This is the location (path) of where your unzipped folder is saved on your computer and is achieved by running a few lines of code that set up your working directory. If you are new to paths and working directories, a succinct introduction can be found here. Furthermore, these tutorials provide instructions on determining the path of your unzipped folder in windows and mac operating systems.
The following code for sets up a working directory. Please note, in python, anything after the "#" symbol is considered to be comments related to the code.
import os #import the os library (enables operating system dependent functionality)
os.chdir('C:\YourFolderPathGoesHere') #change directory
os.getcwd() #get the current working directory to confirm the directory change

The first line of code imports the module that contains the operating system interface (which includes the subsequent functions that allow for changes to the working directory). The second line changes the working directory to where the unzipped folder is saved. The last line confirms the working directory has been changed. If after running the last file the correct folder path of you unzipped folder isn't returned, check to make sure your code and/or your folder path is correct.
Above the console in the "Help" pane, you can take a look of the files loaded in this directory under the "File Explorer" tab.

You can then input the below scripts in the console to load your dataset into the program. Note that the csv file has to be in the current working directory, otherwise an error will be raised.
import pandas #import the pandas data analysis library
data = pandas.read_csv('cchs-82M0013-E-2012-mental-health_F1.csv')

The first line imports the pandas library, which will be used throughout this tutorial. The next line uses the read_csv command in pandas to load the CCHS2012 dataset to the system and assigns it the variable "data". From now on, when you want to refer to your CCHS2012 dataset, you can just use the variable "data".
It is always helpful to get an idea of our dataset before cleaning it. Above the console in the Help pane, by clicking on the tab "Variable explorer" you will be able to see the details of each variable defined in the current console session, including data type and size.
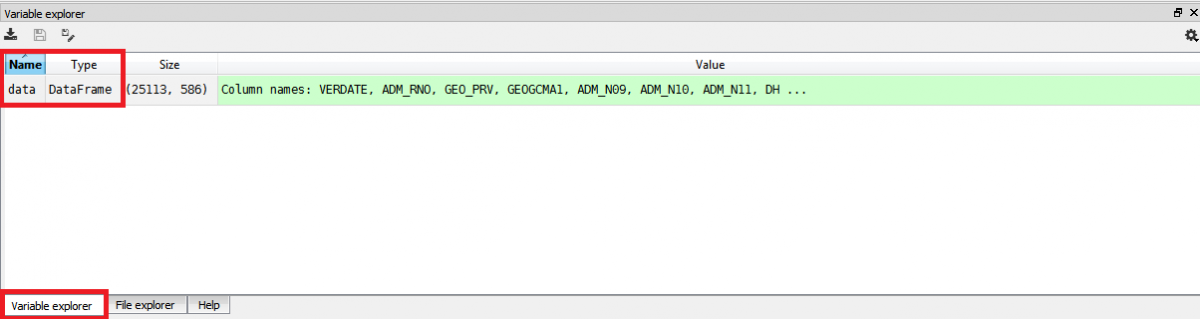
Double-clicking a variable in the "Variable explorer" pane will open a new window displaying the whole dataset.
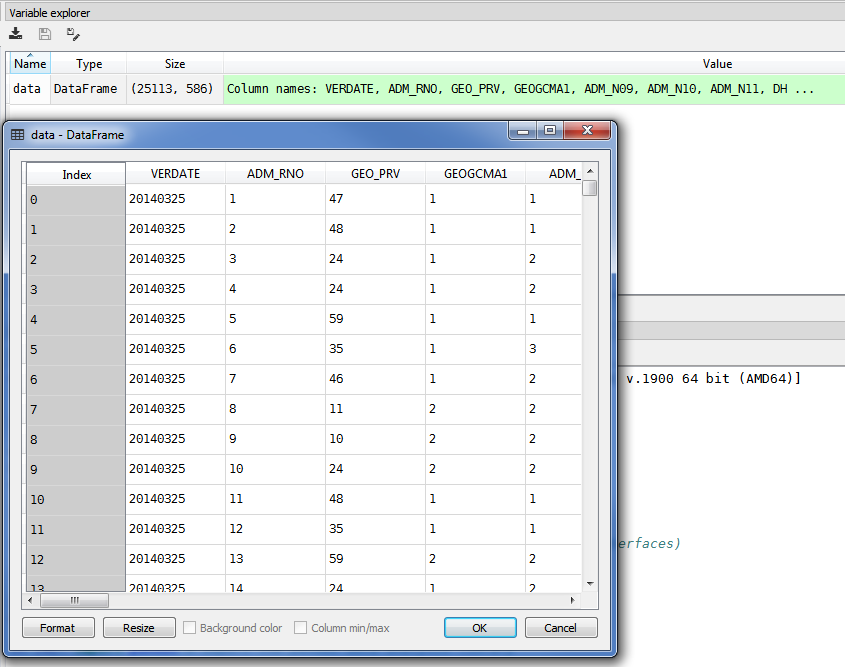
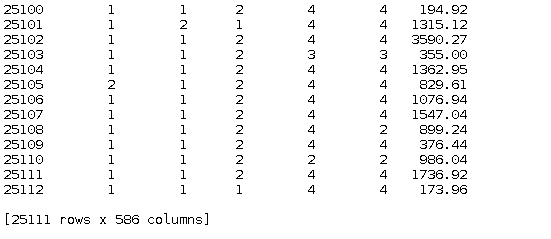
We can also see the dimension of the dataset using the shape command. In our case, the dataset has 25113 rows and 586 columns.
print(data.shape)

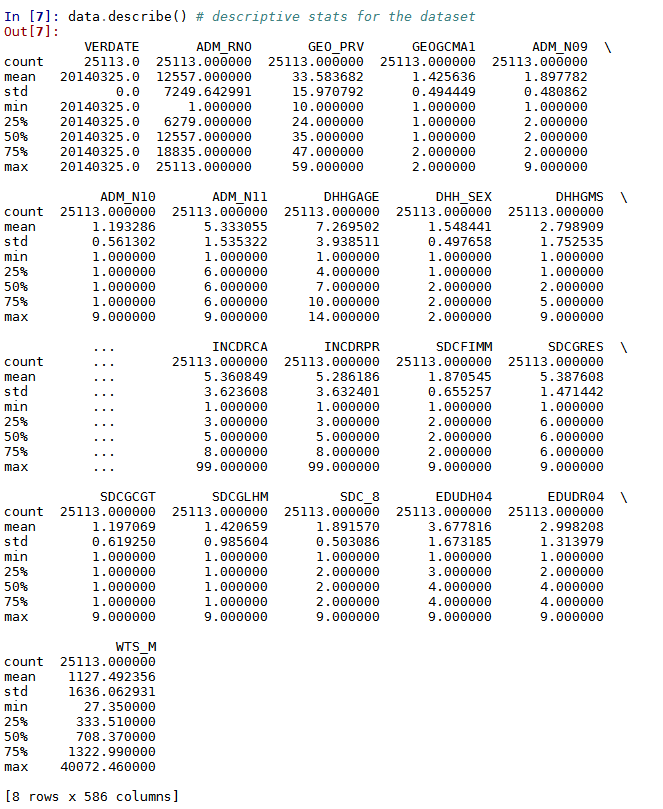
Furthermore, we can view the descriptive statistics of the varaibles in our dataset with numeric values using the describe command.
data.describe()
It is important for our analysis to identify the missing values in our dataset. This can be achieved by setting determined missing values to NaN (missing data) when we are loading the dataset into the program (using the "read_csv" function introduced above).
Suppose a column that's expected to have numerical values has recorded the letter 'g' by mistake in some records. We can use the below code to set these extraneous values to NaN.
data = pandas.read_csv('cchs-82M0013-E-2012-mental-health_F1.csv', header=0, na_values=['g'])
#we can assign the variable 'data_no_gs' for example to retain the original 'data' variable

If a dataset contains missing data indicated by 'NA', you can read the data in as follows:
data = pandas.read_csv('cchs-82M0013-E-2012-mental-health_F1.csv', header=0, na_values=['NA'])

Furthremore, if we want to understand how a particular dataset records missing values to then identify them in the program, we can refer to the dataset's metadata for these details.
In our case, we will refer to the accompanying downloaded codebook, where it states that the value '96' denotes the term 'Not Applicable'. To then set this value to 'NaN' the the following code can be used.
data = pandas.read_csv('cchs-82M0013-E-2012-mental-health_F1.csv', header=0, na_values=[96])
You can find all the rows where a specific column holds NaN values as follows:
data[pandas.isnull(data['GEO_PRV'])]
Though in this case, the column 'GEO_PRV' does not contain any NaN values, resulting in an empty data frame.

Subset
Pandas offers a variety of options for selecting subests of a dataset. Subset selection is simply selecting particular rows and columns of data from your data frame.
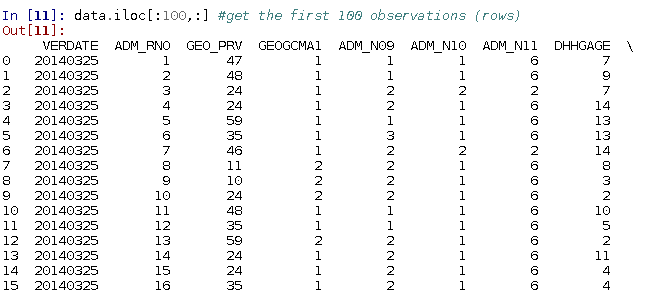
You can create a subset by selecting observations: e.g. get the first 100 observations (rows)
data.iloc[:100,:] #get the first 100 observations in a dataset

... ... ... ... ... ...
By selecting variables: e.g. get the first 100 variables (columns)
data.iloc[:,:100] #get the first 100 variables in a dataset


... ... ... ... ... ... ...
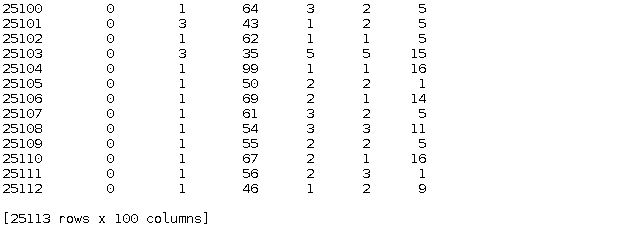
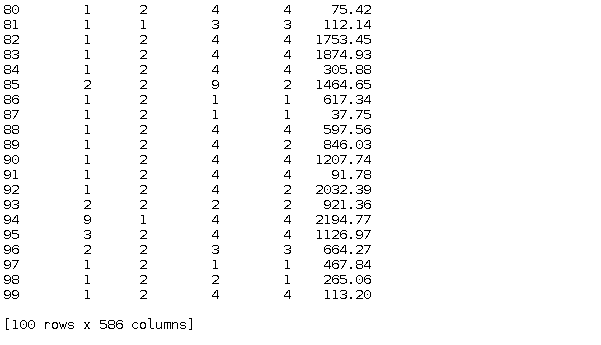
Or by selecting both: e.g. get the first 100 rows and 100 columns of the original dataset
data.iloc[:100,:100] #get the first 100 rows * 100 columns

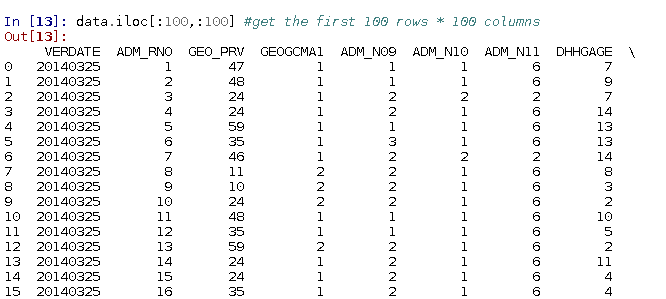
... ... ... ... ... ...

Furthermore, you can create a subset by selecting variable names: e.g. get column “VERDATE”, “ADM_RNO”, and “GEO_PRV”
data.loc[:,['VERDATE', 'ADM_RNO', 'GEO_PRV']]


... ... ... ...

Drop data
Pandas also allows us to drop, or remove, extraneous data from our dataset.
We can drop specific observations: e.g. drop the rows with index 1 and 3
data.drop([1, 3])

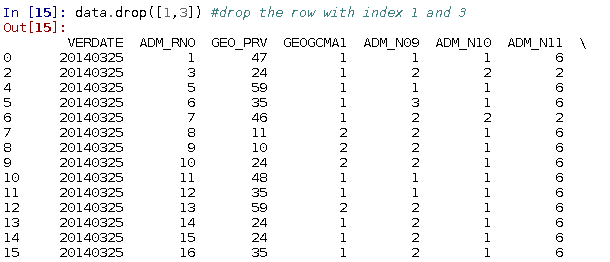
... ... ... ... ... ... ...
Or we can drop variables: e.g. drop columns with header "GEOGCMA1" and "ADM_N09". Note that in the command, axis=1 indicates a column to be dropped. Axis=0 indicates a row/index to be dropped.
data.drop(['GEOGCMA1', 'ADM_N09'], axis=1)

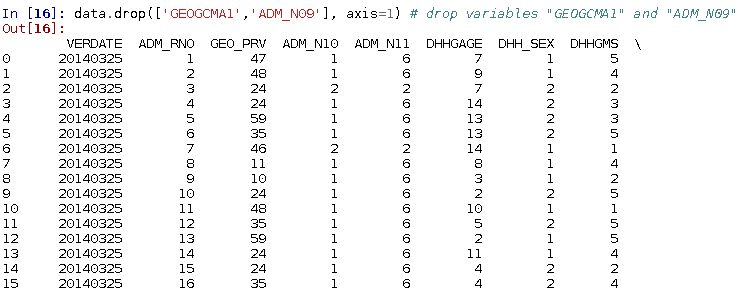
... ... ... ... ... ... ...

Transform data
In many instances, it will be necessary to transform your dataset to a form you can work with.
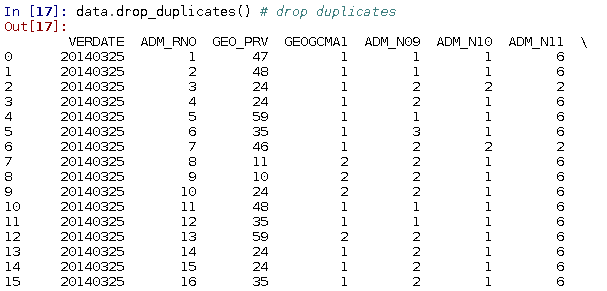
You might have to remove duplicate observations:
data.drop_duplicates()
In our case, there are no duplicate rows that need to be dropped.

... ... ... ... ... ... ...

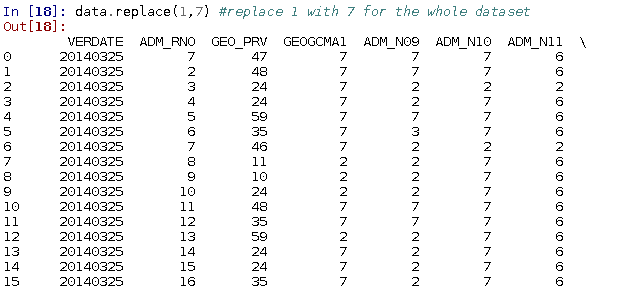
You might want to replace values. To replace all instances of the value 1 with the value 7 for the entire dataset you can use the following code:
data = data.replace(1, 7)
The replace function returns a copy of the altered dataset but keeps the original dataset intact. In order to retain your changes, it is important to assign a variable to the returning dataset. Using data = replaces the previous dataset with the renamed dataset (in this case, the original dataset 'data' is replaced with the result of the replace function).

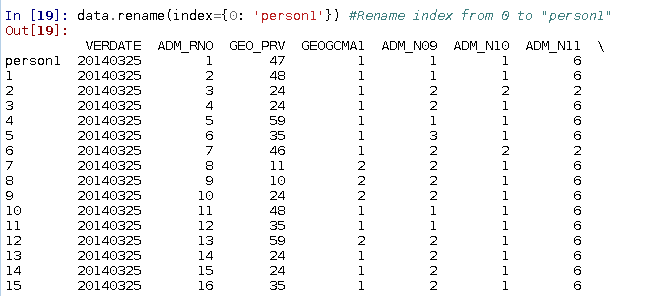
You might want to rename an index. To rename the index '0' with 'person1' the following command can be used:
data2 = data.rename(index={0: 'person1'})
Again, in order to retain your changes, it is important to assign a variable to the returning dataset. Using data2 = ensures the changes are saved to another varaible, keeping the original data frame, named 'data' in tact.

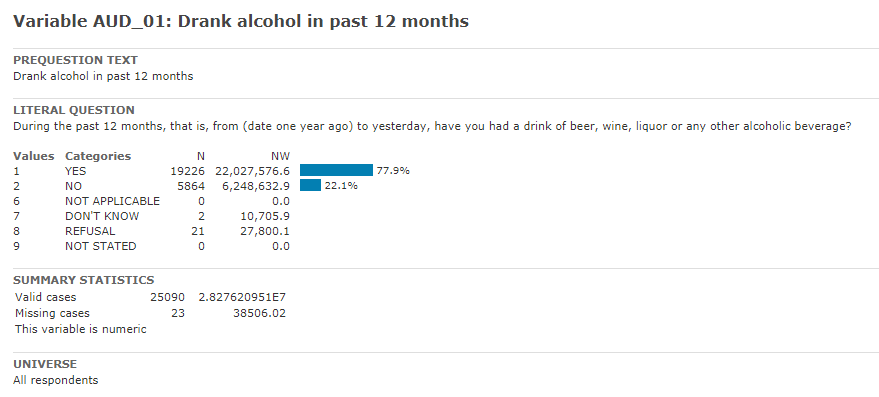
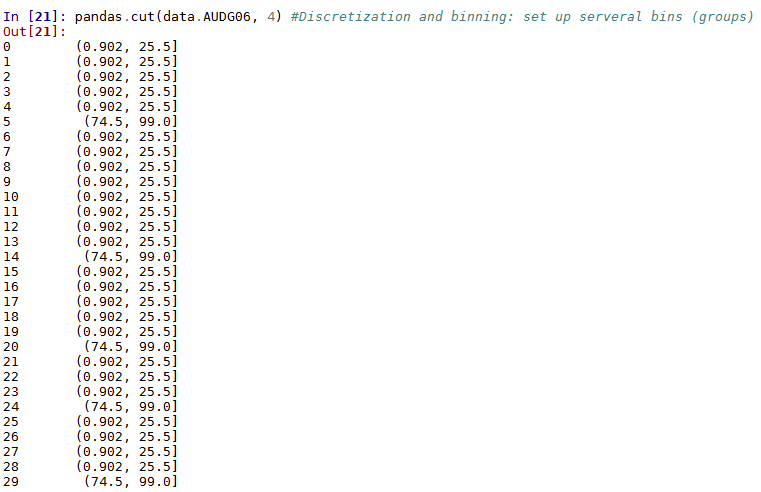
Sometimes numerical values make more sense if clustered together.This is called discretization or binning. For example, if we’re trying to differentiate respondents based on their drinking habits, the exact number of drinks might not matter to us. We can use a cut command to group records based on discrete numbers.
Here we are dividing the survery's respondents in 4 groups based on the "Variable AUDG06: Number of drinks per day on days when drank in past 12 months".
pandas.cut(data.AUDG06, 4)
...
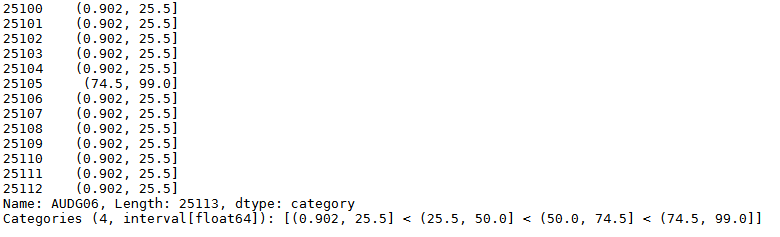
At the bottom of the result, it displays the break values of the dataset for the four categories divided.
Create new variables
We can create a new column “CITIZEN” and designate the value for all observations to be 1:
data.assign(CITIZEN = 1)

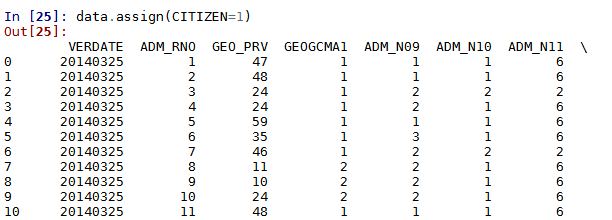
...
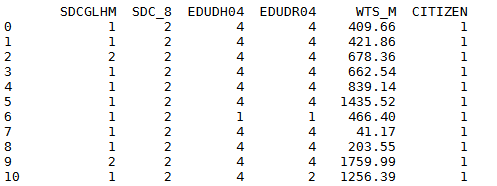
You can see a new column "CITIZEN" is added in the image at the end of the dataset.
Rename variables
To rename the column "ADM_RNO" to "ADM" and the column "GEO_PRV" to "GEO", the following code can be used:
data.rename(columns={'ADM_RNO':'ADM', 'GEO_PRV':'GEO'})

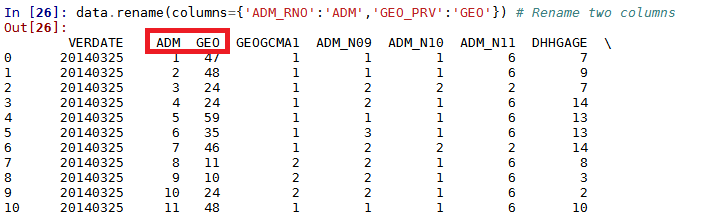
Merge two data sets
Sometimes, it is necessary to merge disparate datasets.
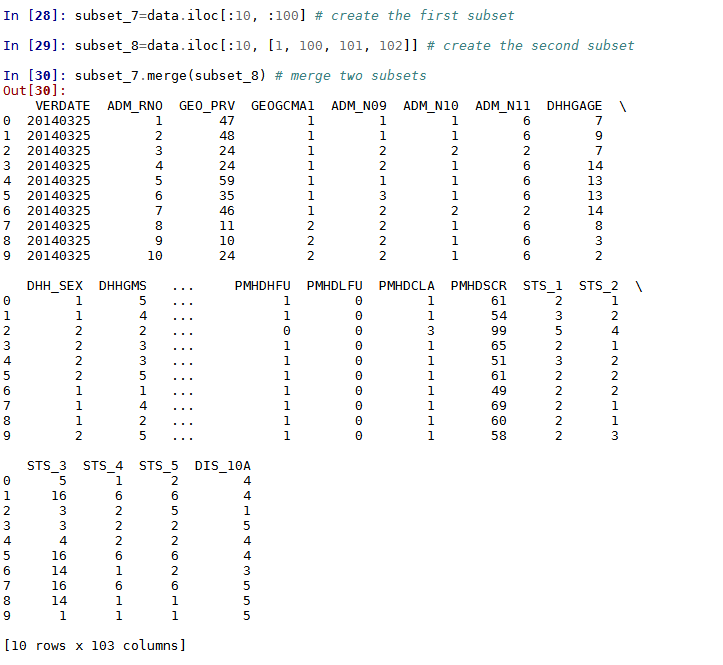
In order to demonstrate the merge command, we will first select and 'save' 2 subsets from our dataset that we can then merge. It is important to remember that we are merging these datasets based on a unique shared key, the first column (Index), and as a result both subsets will share this column. Subset_7 will include the first 10 observations with columns 0 - 99; subset_8 will include the first 10 observations with columns 1, 100, 101 and 102.
subset_7=data.iloc[:10, :100] #create the first subset
subset_8=data.iloc[:10, [1, 100, 101, 102]] #create the second subset
To then merge our subsets we will use the following code:
subset_7.merge(subset_8) #merge the two subsets
The merged dataset should have the dimension 10*103 (as each subset had 10 rows and now invludes the combined columns 0-102).



A few last words
This concludes the Cleaning Data in Python tutorial, but it’s only the beginning for an aspiring Data Analyst. Here we list some resources that you might find helpful:
- Python for Data Analysis: http://shop.oreilly.com/product/0636920023784.do
- A list of packages’ website:NumPy: http://www.numpy.org/; matplotlib: http://matplotlib.org/; pandas: http://pandas.pydata.org/; SciPy: http://www.scipy.org/;sklearn: http://scikit-learn.org/stable/
- Getting Started with Python for Data Science: https://www.kaggle.com/wiki/GettingStartedWithPythonForDataScience
- Google’s Python Class (for people new to Python): https://developers.google.com/edu/python/
- OpenIntro Statistics: https://www.openintro.org/stat/textbook.php
- Last but not least, Google is your friend and questions you’ll meet have probably been asked before.
Enjoy analyzing data!